데이터를 분석할 때 첫 단계로 대부분 탐색적 데이터 분석(EDA)을 하라고 한다.
EDA
탐색적 데이터 분석(Exploratory Data Analysis)
EDA는 탐색적 데이터 분석을 말한다. 이는 데이터 분석 과정에 대한 개념으로, 데이터를 분석하고 결과를 산출하는 과정에 있어서 여러 방면으로 해당 데이터에 대한 '탐색과 이해'를 기본으로 해야 한다는 것이다.
초기 Raw Data를 파악할 때부터 데이터를 잘 파악하고, 다각도로 분석해보며 유의미한 데이터를 만드는 것이 상당히 중요하다. 그렇게 데이터를 정확히 파악해야만 데이터를 통해 문제 해결을 할 수 있게 된다.
실습을 위해
Kaggle: Your Machine Learning and Data Science Community
Kaggle is the world’s largest data science community with powerful tools and resources to help you achieve your data science goals.
www.kaggle.com
대표적인 데이터 분석 경연대회 플랫폼인 Kaggle에서 Data Set을 구하였다.
우선 python venv를 활용하여 가상 환경을 구성한 후,
vscode에서 jupyter notebook 환경을 구성하였다.

가상 환경 설정 및 vscode 설정은 추후 따로 포스트를 작성하도록 하겠다.
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt우선 기본적으로 사용할 패키지들을 import 해주었다.
1. pandas: 데이터 분석을 위한 툴로 데이터 분석 및 조작을 위한 해주는 라이브러리
2. numpy: C언어로 구현되었으며 고성능의 수치계산을 위한 라이브러리
3. matplotlib: 데이터를 다양한 그래프로 만들어 주는 시각화 패키지
4. seaborn: Matplotlib을 기반으로 다양한 색상 테마와 통계용 차트 등의 기능을 추가한 시각화 패키지

data = pd.read_csv('./data/StudentsPerformance.csv')그리고 준비한 data set을 pandas를 통해 불러왔다.
|
read_csv
|
pandas의 메서드. 인자를 통해 csv파일을 Pandas DataFrame으로 읽어온다. |


data.shape, data.columns그 후 읽어 들인 data의 정보를 확인해보았다.
| shape | 행과 열의 개수를 튜플로 반환한다. |
| colums | 열의 이름들과 데이터 형테를 반환한다. |
| describe | Pandas DataFrame의 모든 숫자 열에 대한 다양한 기술 통계 측정값을 나열한다. |

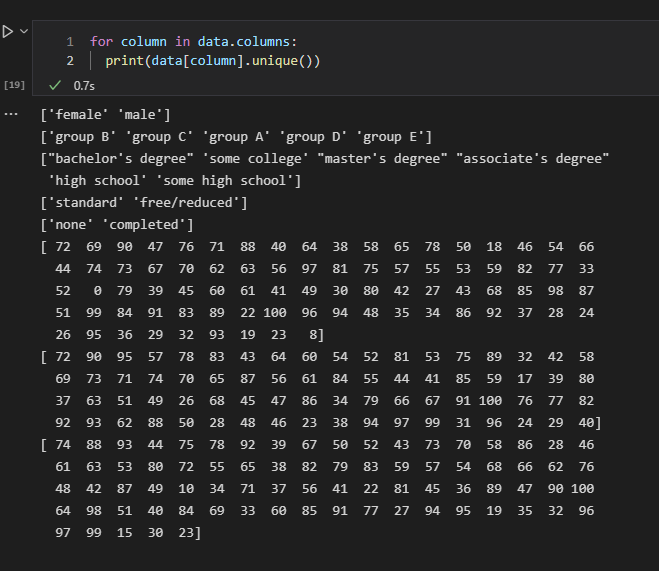
data.nunique()
data["gender"].unique()| nunique | 각 열에 대한 고유 값의 수를 반환한다. |
| unique | 특정 데이터에 어떠한 고유값들이 있는지 반환한다. |
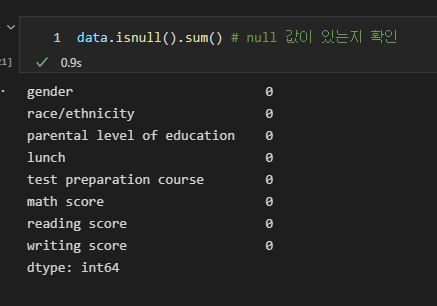
data.isnull().sum() # null 값이 있는지 확인| isnull | missing value가 존재하면 True를 반환한다. |
| sum | 각 column 별 missing value의 개수를 반환한다. |
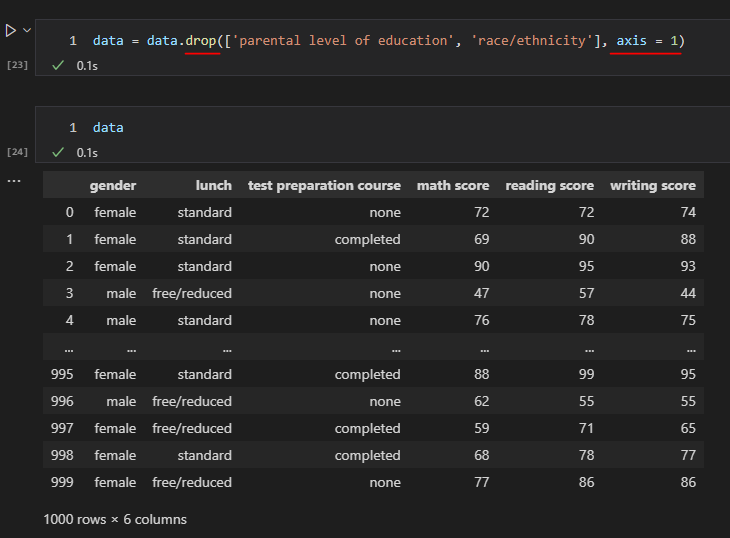
data = data.drop(['parental level of education', 'race/ethnicity'], axis = 1)| drop | 행 또는 열을 삭제한다. |
df.drop(labels=None, axis=0, index=None, columns=None, level=None, inplace=False, errors='raise')labels : 삭제할 레이블명을 기입해준다.
axis : {0 : index / 1 : columns} labels인 수를 사용할경우 반드시 지정해주어야 한다.
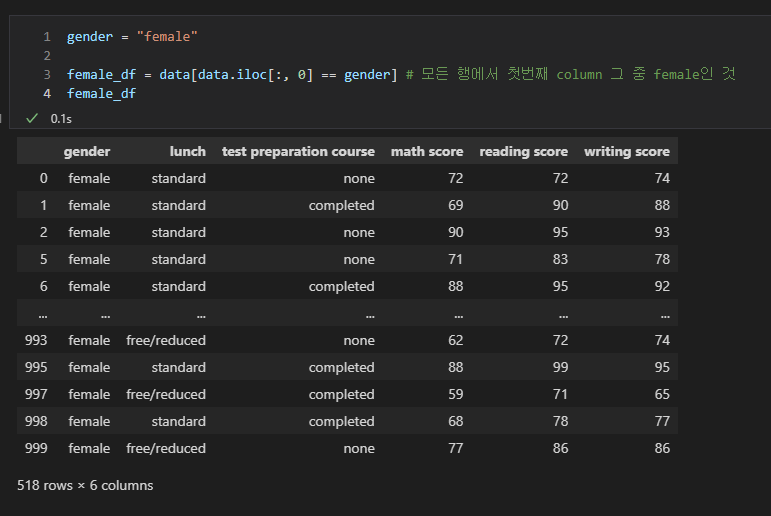
gender = "female"
female_df = data[data.iloc[:, 0] == gender] # 모든 행에서 첫번째 column 그 중 female인 것
female_df
female_df["math score"].max()
female_df["math score"].min()
female_df["math score"].mean()
female_df["math score"].std()차례대로 특정 열의 최댓값, 최솟값, 평균, 표준편차를 계산한다.
| max | 최댓값 |
| min | 최솟값 |
| mean | 평균 |
| std | 표준편자 |

data.info()데이터에 대한 전반적인 정보를 확인할 수 있는 함수이다.
| info | DataFrame을 구성하는 행과 열의 크기, column명, column을 구성하는 값의 자료형을 알려준다. |
Data Cleansing
이번엔 다른 data set을 이용하여 데이터를 원하는 대로 정리해보도록 하겠다.
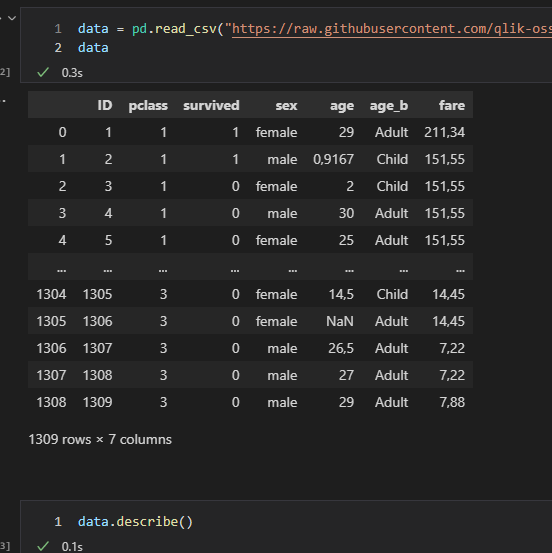
초기 Data Frame의 보습은 위와 같다.
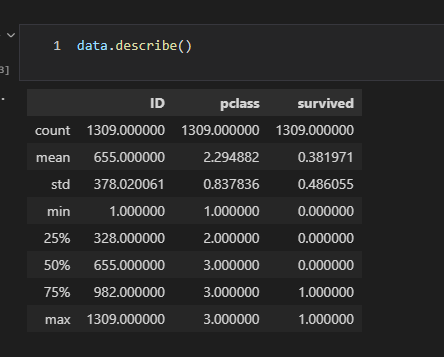
정리하기 전 describe 실행 시
ID, pclass, survived에 대한 요약 통계만 나타났다.
age와 fare 열도 숫자 데이터이지만 숫자로 인식되지 못한 것이다.
'그래서 보통 데이터 제공자는 믿어도 데이터는 믿지 말라'
라는 말을 한다고 한다.
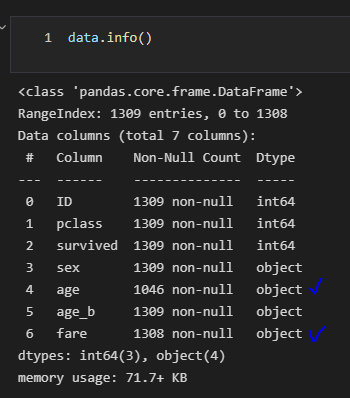
자료형을 확인해보니 object로 인식되고 있었다.
숫자 데이터에 구분자로 ' , ' 가 들어가 있어 그런 것이었다.
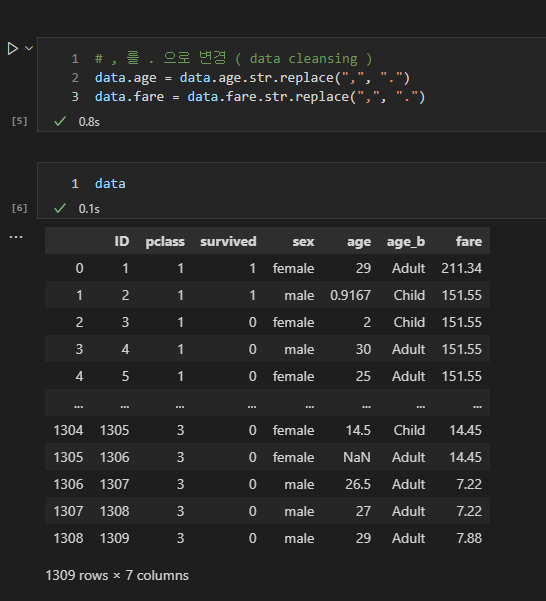
그래서 ' , ' 를 ' . ' 로 변경해주었다.
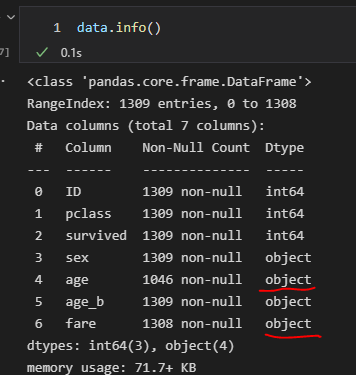
그러나 여전히 object로 인식되고 있었다.
이는 pandas 객체의 타입을 캐스팅해주지 않아서 그런 것이었다.
적절하게 숫자 구분자는 제거해주었으니,
pandas.DataFrame.astype
https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.astype.html
pandas.DataFrame.astype — pandas 1.4.2 documentation
Cast a pandas object to a specified dtype dtype. Deprecated since version 1.3.0: Using astype to convert from timezone-naive dtype to timezone-aware dtype is deprecated and will raise in a future version. Use Series.dt.tz_localize() instead. Note that usin
pandas.pydata.org
를 이용하여 원하는 타입으로 변경해주도록 하겠다.
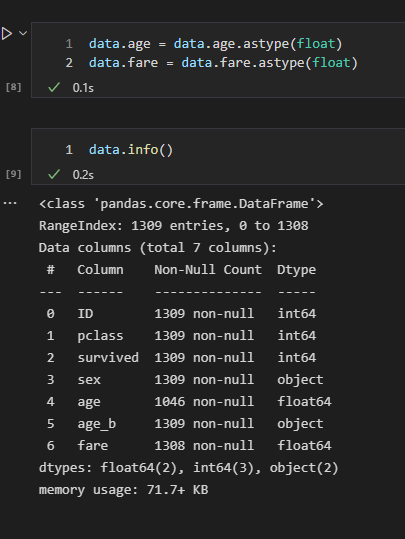
data.age = data.age.astype(float)
data.fare = data.fare.astype(float)드디어 숫자로 인식되었으며,
다시 통계를 확인해보니
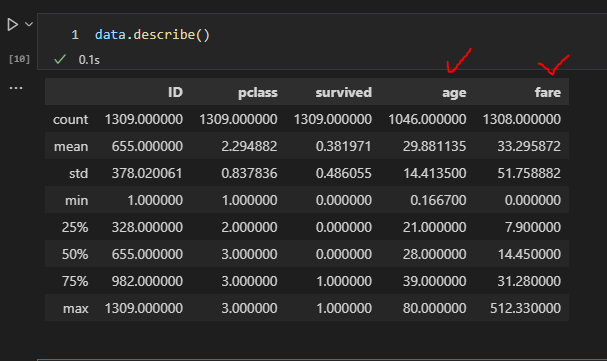
age와 fare 값도 분석할 수 있게 된 것을 확인할 수 있었다.
추후 DataFrame 내의 NaN 값을 처리하는 과정도 추가하도록 하겠다.
참고자료